How can a neural net make art?
In the previous installments, I wrote a bit about what a neural net model is, how they generate output from an input, and how training works. And now, I’m going to try to explain (briefly) how we get from those building blocks to something that can take as input “a painting of a horse”, and produce this:

Building systems from a model (or sets of models)
Overcoming limitations of the simple neural network model
At the basic level we’ve been describing so far, you have a model, which produces a set of outputs from a set of inputs. The model always produces the same output from the same input, and doesn’t know anything about the context of what it’s being asked to do.
You can do a lot of useful work with this simple kind of model. You can identify objects in a photograph, guide a cruise missile, read hand-written addresses from envelopes…
But this kind of model is really bad at any task where the “right” answer might change over time, or where previous output might influence future outputs. It’s frozen in time, unable to learn, or even to remember what’s happened before.
Adding “memory” to a network
An obvious thing to try is feeding some of those outputs back into some of the inputs. This gives you something called a recurrent neural network, which adds memory (an awareness of its previous state) to the network. This is super-useful for something like recognizing (or generating) human language, because what’s come before informs the meaning of what comes after. If you’re trying to predict what comes after “Trump” in a sentence, it matters a lot whether “President” or “Card Game” occurred previously.
Pitting neural networks against each other
If you have a model which has been trained to recognize objects in pictures (for example), you can use it to “test” the output from another network, and give it automated feedback on how well it’s doing at producing output that “looks the same” as the training data. They call this a Generative Adversarial Network, and it’s essential to the production of “AI Art”, as we know it today.
I’m not going to even try to explain that in any great detail (because, seriously, just skim that Wikipedia article – it’s dense), but I think it’s important to understand that there’s two neural networks involved: a discriminator, which is trained to recognize certain characteristics of an image, and a generator, which attempts to create new images that are “close enough” to pass the discriminator.
How Stable Diffusion works
There are two pieces to Stable Diffusion (and most other AI art systems). There’s a generator, which creates images, and a discriminator, which rates them, according to the prompts that you feed into the system.
Between the two of them, there’s a sort of interactive dialog, where the generator proposes an image, the discriminator compares it to what the user asked for, and provides feedback to the generator for another attempt. This is repeated a specified number of times, with the generated image getting closer to the requested output each time (ideally, at least).
The user inputs into the system
Stable Diffusion has a bewildering set of inputs you can make. But the most-important ones are these three:
- A text prompt
- The number of times to repeat the feedback loop (steps)
- The seed, which is just a number
How to build a discriminator
If you want to teach a neural network how to identify objects, moods, media, artist styles, and artistic movements, then what you need is a database of images, each tagged with text telling you which of those things are represented in each image.
First, you need a big database
The LAION project is exactly that – a group of truly enormous datasets, created from billions of images hosted on the public internet, catalogued by keywords. It’s a non-profit, open-source project, intended to “liberate machine learning research”. Most (all?) image generation tools in popular use today have created their training data from some part of the LAION database.
An interesting thing about LAION is that they don’t host any images themselves. As they say in their FAQ:
LAION datasets are simply indexes to the internet, i.e. lists of URLs to the original images together with the ALT texts found linked to those images.
https://laion.ai/faq/
But, be careful which images you use as input
There has been some controversy about the use of these data sets for commercial products, outside of the AI research that they’d originally been created for. They have endeavored to remove “illegal images”, but the datasets still contain nudity, gore, medical diagnostic images, revenge porn, crime scene photographs, and potentially other horrible things. For GDPR privacy concerns, they’ve provided a web form you can fill out if you happen to find a picture of yourself, tagged as you, somewhere in their database.
I’ll be revisiting the ethics of this data source in a future installment.
Then it’s “just” a matter of training
As you might imagine, doing much of anything with a billion-image dataset is a very compute-intensive operation. That’s why many people in the “AI Art” space are not generating their own models from the LAION dataset directly. This is why Stable Diffusion is such a big deal for AI art generation – they’ve already done the hard work of downloading the images and text, and then training a discriminator network to recognize all of those terms and images. They then packaged it all up, along with a generator and
And then, there’s the generator
I don’t understand this part very well
Sorry, but I’m going to get even more hand-wavy here, because the generator is both less interesting, and harder to understand, than the discriminator. So I’ve done less investigation of the techniques used here, because it’s just less interesting to me, especially from the moral/ethical standpoint.
How the Stable Diffusion generator works
When you start image creation, the generator creates an image filled with random blobs of color. It looks something like this:

This is a pseudo-random process, created from the “seed” which is just a number. Entering the same seed always gives the same initial image. There’s nothing in the generator that knows anything at all about what prompt you’ve given.
The feedback loop
After the generator creates an image, the discriminator then gives feedback on how close that is to what was requested, in this case “painting of a horse”. Obviously, at this initial stage, it’s “not very close”. But the discriminator provides some additional inputs to the generator, which then takes another shot at generating an image.
Putting it all together
Let’s go through the process to show how we got the image at the top of this blog post. Starting from that random blob of colors, we run through the loop of generation and feedback 25 times.
Every time the generator and discriminator complete one round of generation and feedback, a new image is created that incorporates feedback from previous rounds.
Here’s what we get from round 2:
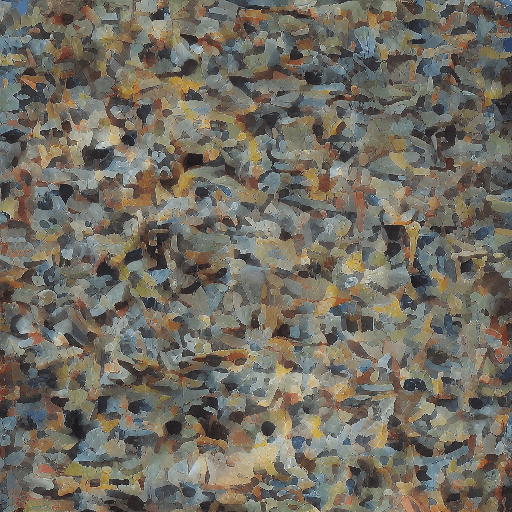
As you can see, it’s still very random, but it’s starting to look much more “painterly” due to fewer contrasting edges, and is trending toward a more “horse-like” color palette. The small blobs of color are also starting to coalesce into larger areas.
With two more iterations, we get this:

Wow, that’s totally a horse. But it’s looking in a different direction, and is in a completely different, more impressionistic style, than the final result. How does that happen?
Neither of the models actually understands what you want
The generator, by design, is completely generic. It can create a huge variety of kinds of images, and doesn’t know anything about art. It’s just trying things out, incorporating feedback from the discriminator, and trying again.
The discriminator, on the other hand, can tell whether an image is “more like” the text prompt, or less like it. But it also doesn’t understand the text of the prompt in any great detail. It doesn’t care about sentence structure, it doesn’t understand concepts like more or less, or directions like up and down.
For example, if I switch around the words in my prompt, and keep the rest the same, here’s what I get for “a horse of a painting”
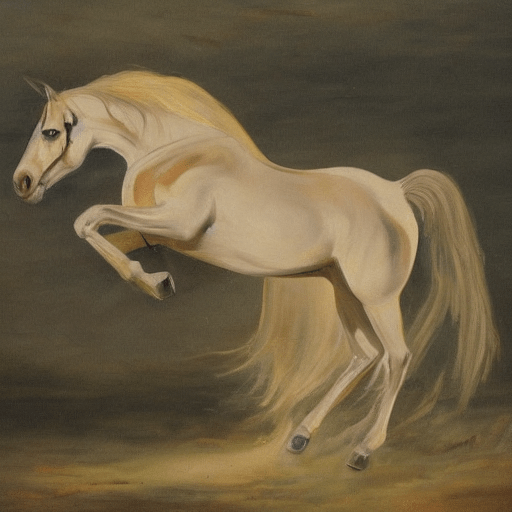
Neat – it’s the same color palette and style, but now it’s jumping. So it’s not strictly just matching on the nouns in the prompt, but it’s also not really attaching conventional meaning to the provided words.
Prompt Engineering
There is a whole “art” of developing prompts to get a particular desired output. People call it “prompt engineering“, but it’s a lot more of a folkloric, anecdote-based trial and error process than it is any kind of scientific/engineering endeavor.
Mostly, this comes down to the opaqueness of the underlying model. A bunch of inputs got fed into the discriminator, and it has some internal model of what words go with which images, but it’s not clear from the outside what those associations are.
And that’s how it works
So, that’s the current state-of-the-art in AI image generation. Things change rapidly, though – Stable Diffusion 2.0 just came out earlier this year, and there is intense competition in the AI Art as a Service commercial space, where companies are competing to see who can produce “better” results, with easier customization, and specializing in higher-value outputs.
That same Stable Diffusion algorithm and models can be used for everything from photo editing, to making cool selfies of yourself as an Elf, to generating commercial clip art, and to some darker purposes, as well.
Next Up
Now that you know how it works, is it legal, moral, and ethical for you to use tools like Stable Diffusion?

Leave a comment