How does AI work, anyway?
If you haven’t read the previous post, you might want to do so now.
Okay, we’re going to get into a little bit of math here, but I promise I’ll try to keep it light.
Systems of equations
You may remember from Junior High School Math, being presented with sets of equations to solve, like this:
3x + 4y = 5
6x + 7y = 8We learned a bunch of methods to solve these, but once they get more than a little bit complicated, you wander into the realm of Linear Algebra, and matrix math.
Matrices
Matrices represent equations as a series of numbers, one for each term in the equation, so the above would turn into:
| 3 | 4 | 5 |
| 6 | 7 | 8 |
Once you have those numbers in a matrix, there is a simple, mechanical process you can follow to manipulate the matrix, and solve the equations. These sorts of matrix multiplications are much used in, for example, computer graphics…
Okay, but how does all of this relate to neural networks? I’m so glad you asked!
Network Topology
When modeling a neural network, you need to determine the strength of the connections between all of the neurons.
If we look at a diagram of a simple network, it might look like this:
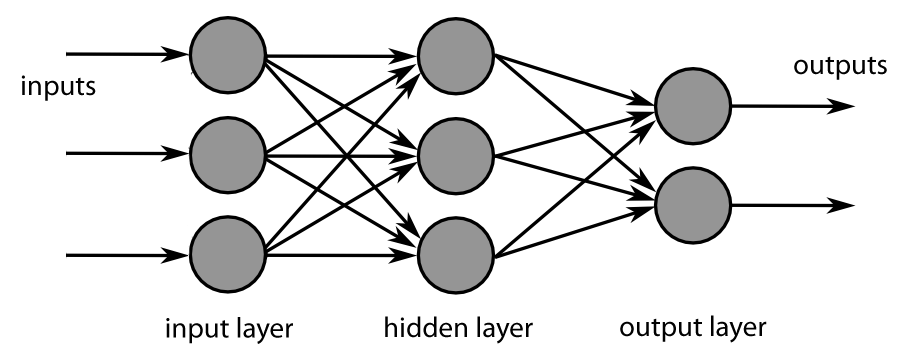
So, you have some “input” neurons, which accept the input to the network, and “output” neurons, which provide the output from the network. And in the middle, you have one or more “hidden” layers. And each of the connections between the neurons (represented by arrows in the diagram) have different strengths that can be either positive or negative. So a single number can be used to set the strength of each connection, from, say, -1 to +1.
So, to figure out the state of the net, you start on the input side, take each of the input states, multiply by the weights of their connections to the next layer, and sum them up. Then the process repeats on the next layer across, until you reach the output.
Let’s look at just the middle neuron in that diagram, and set up some inputs and connection weights:
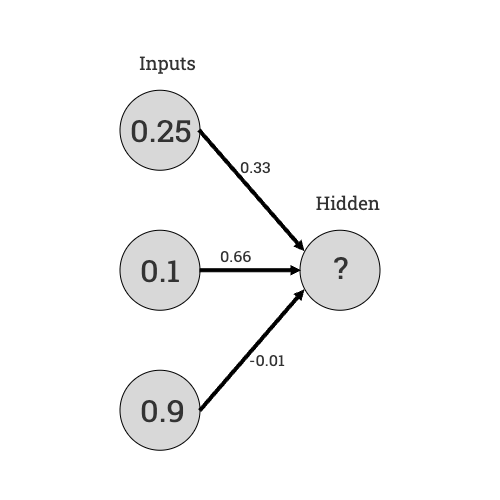
So, to figure out the state of the hidden neuron, we take the inputs, multiply by the weights of their connections, and sum them up:
0.25 x 0.33 + 0.1 x 0.66 + 0.9 x -0.01 = 0.1395There’s one last step, where the sum goes through a function to “normalize” the value, so that even if all of the inputs are +1.0, and all of the weights are +1.0, the result comes out in the range of 0.0 to 1.0. But that’s the process, in a nutshell.
All of these connection weights, and the current values of each neuron, are stored in matrices of numbers. Note that the value of each neuron depends only on the values and weights of the connections to its “left”. There are no connections between the neurons in any one layer (vertically, in that diagram). This means that the value of all the neurons in any layer can be calculated simultaneously, limited only by the number of GPU cores available.
Multiplying a “vector” of inputs by another “vector” of weights, and summing the results, is exactly the kind of problem that GPUs were designed to excel at.
So, you just repeat that calculation for every neuron in each layer in the network, until you get your output values. Simple stuff, right? So where does the magic come in?
Quantity has a quality all its own
Take a look at that first diagram, again. Imagine you want to figure out what mortgage terms to offer someone on a home purchase. Your input values might be their income, the cost of the house, and their credit rating. And the output values might be the interest rate and down payment they’d need to provide.
The hidden neurons in the middle of the diagram represent (along with their weights coming in and going out) literal “hidden variables” in the evaluation of that person’s credit risk. So, one neuron might represent “current debt load”, and have a positive connection to their current debt, and a negative connection to their income. And another might represent “house affordability”, and would have a negative connection to the house price, and a positive connection to their income.
You could, actually, make a net as simple as that, and use it to calculate mortgage terms. But, in practice, you’d have a whole lot more potential inputs you’d want to have into the evaluation. You might include the type of home (standalone, attached, manufactured), the general trend of home prices in the neighborhood, information about the person’s assets, other than income, etc, etc.
And once you do that, the meaning of the individual hidden neurons in the inner layers becomes a lot more abstract. You can’t easily point at a single neuron, and say “this value represents debt load“, for example. This lack of transparency is a fundamental problem with auditing the decision-making process of these models, and is an active area of research (that I’m not very optimistic about). Right now, one of the best ways to validate an AI’s decision-making is to look for patterns of bias in the outcomes, much like we do with civil rights investigations. More on that problem, later..
It’s not unusual for neural networks used in production code to have millions of neurons, multiple hidden layers, and a correspondingly large number of connections. For a neural net that processes image data, the input layer might have as many neurons as there are pixels in the input image. The hidden layers and output layer might be larger or smaller than the input, depending on what you’re trying to calculate as output.
Training is where the magic really happens
Once you have set up a network, you then need to “train” it to do the work you want it to do. We’ll get into the “how” in a future post, but for now, keep in mind that there is a “training” process that determines what output the neural net produces for a certain set of inputs.

Leave a comment